

AI Buzzwords, Decoded
A Plain-English AI Glossary for Busy Leaders

TL;DR: This glossary explains the 30–40 AI terms you actually need. Focus on how each concept shows up in products, budgets, and risk reviews—not the math behind it.
Estimated read time: ~9 minutes
🧭 How to use this glossary
Skim the bolded term, read the one-liner, and note the “why it matters.” If you remember only that part, you’ll still make better decisions in meetings.
🧩 Core concepts
Artificial Intelligence (AI): Umbrella term for systems that perform tasks we’d call “intelligent” if done by people (classifying, predicting, generating). Why it matters: Sets the scope—many flavors, not just chatbots.
Machine Learning (ML): Software that improves its predictions from data rather than hard-coded rules. Why it matters: Most practical AI in products is ML under the hood.
Deep Learning: A subset of ML using multi-layer neural networks. Why it matters: Powers modern vision, speech, and large language models.
Neural Network: A stack of simple math units (“neurons”) connected in layers. Why it matters: Design and size influence accuracy, cost, and speed.
Parameter: A learned weight inside a model (think: adjustable knob). Why it matters: More parameters often means higher capability—but also higher cost.
🗣️ Language & multimodal models
Large Language Model (LLM): A model trained to predict the next token (piece of text). Why it matters: Drafts, summarizes, translates, and reasons within limits.
Token: A chunk of text (word/part of a word) used for billing and sizing context. Why it matters: Costs scale with tokens in + tokens out.
Context Window: How much the model can “read” at once. Why it matters: Bigger windows can handle longer docs—at higher cost.
Multimodal Model: Handles more than text (images, audio, video). Why it matters: Enables use cases like “read this chart” or “summarize this call.”
Hallucination: A confident but incorrect answer. Why it matters: You need grounding and review for consequential tasks.
Grounding: Supplying the model with authoritative context (docs, data) so it cites facts rather than guesses. Why it matters: Reduces hallucinations, enables compliance.
🛠️ Working with models
Prompt: The instruction and information you give a model. Why it matters: Good prompts save money and improve consistency.
System Prompt / Instructions: Persistent rules the model should follow (“you are a helpful support agent…”). Why it matters: Encodes tone, constraints, and role.
Prompt Template: A reusable prompt with placeholders for variables. Why it matters: Turns ad-hoc prompting into a repeatable process.
Temperature (and Top-p): Controls randomness/creativity of outputs. Why it matters: Lower for precision of answer, higher for brainstorming.
Tool Use / Function Calling: Letting the model call external tools (search, database, calculator). Why it matters: Upgrades a chatbot into a useful assistant.
Agent: A loop where the model plans, calls tools, and iterates, so it perform tasks. Why it matters: Powerful, but needs limits to avoid cost or risky actions.
Inference: Running the model to get an output. Why it matters: Primary driver of your per-use costs and latency.
Latency / Throughput: How long one response takes and how many you can process at once. Why it matters: Affects SLAs and user satisfaction.
🔎 Data & retrieval (the “memory” layer)
Embedding: A numeric representation of text (or image/audio) capturing meaning. Why it matters: Enables “search by meaning,” not just keywords.
Vector Database: Stores embeddings and finds nearest matches quickly. Why it matters: Foundation for smart search and assistants over your content.
RAG (Retrieval-Augmented Generation): Retrieve relevant snippets → feed to the model → generate an answer with citations. Why it matters: The standard pattern to make AI factual based on provided knowledge and up-to-date on your data.
Chunking: Splitting documents into bite-sized pieces before embedding. Why it matters: Improves retrieval accuracy and cost.
Relevance / Top-k: How many snippets you fetch for the model (k). Why it matters: Too few misses facts; too many bloats cost and noise.
🎓 Training & adaptation
Pretraining: Initial learning on large public datasets. Why it matters: Gives models broad abilities.
Fine-Tuning: Additional training on your labeled examples to enforce style, format, or behavior. Why it matters: Makes outputs consistent; not a way to “upload knowledge.”
Instruction Tuning / Reinforcement Learning from Human Feedback (RLHF): Methods to make models follow human instructions and preferences. Why it matters: Improves usefulness and safety.
Low-Rank Adaptation (LoRA) / Parameter-Efficient Tuning: Techniques to adapt big models cheaply by training small adapters. Why it matters: Lowers cost to customize.
Distillation / Quantization: Shrinking models or using lower-precision numbers. Why it matters: Faster, cheaper inference—sometimes with small quality trade-offs.
📊 Quality, evaluation, and monitoring
Eval Set: A fixed set of real prompts with expected outcomes. Why it matters: Your scoreboard for model changes.
Human-in-the-Loop (HITL): People review/approve AI outputs. Why it matters: Adds safety and learning for high-impact tasks.
Guardrails: Rules that restrict inputs/outputs (redaction, allow/deny lists, content filters). Why it matters: Reduces risk and enforces policy.
Feedback Loop: Capturing user edits/ratings to improve the system. Why it matters: Drives continuous quality gains.
Drift: Quality degrades over time as data or behavior changes. Why it matters: Requires re-evaluation, re-embedding, or model updates.
🔐 Security, privacy, and governance
PII (Personally Identifiable Information): Data that identifies the user as a person (full name, address, ID number). Why it matters: Must be protected, redacted, and handled per policy/law.
Data Leakage: Sensitive info exposed by accident (logs, prompts, outputs). Why it matters: Set retention, masking, and access controls.
Red Teaming: Deliberately stress-testing for failures and abuse. Why it matters: Reveals weaknesses before attackers or customers do.
Isolation / Data Residency: Keeping data in specific regions or separate environments. Why it matters: Compliance and contractual obligations.
Audit Logging: Recording who did what, when, and with which data. Why it matters: Essential for investigations and certifications.
💸 Cost & architecture basics
Usage-Based Pricing: Paying per token, image, or minute. Why it matters: Aligns cost with usage; watch for spikes.
Caching: Reusing previous results when the same question appears. Why it matters: Cuts latency and cost dramatically.
Orchestration: The glue code connecting prompts, tools, retrieval, and business logic. Why it matters: Where reliability and scalability live.
Fallback & Routing: Sending requests to different models or paths based on the task. Why it matters: Balances quality, cost, and uptime.
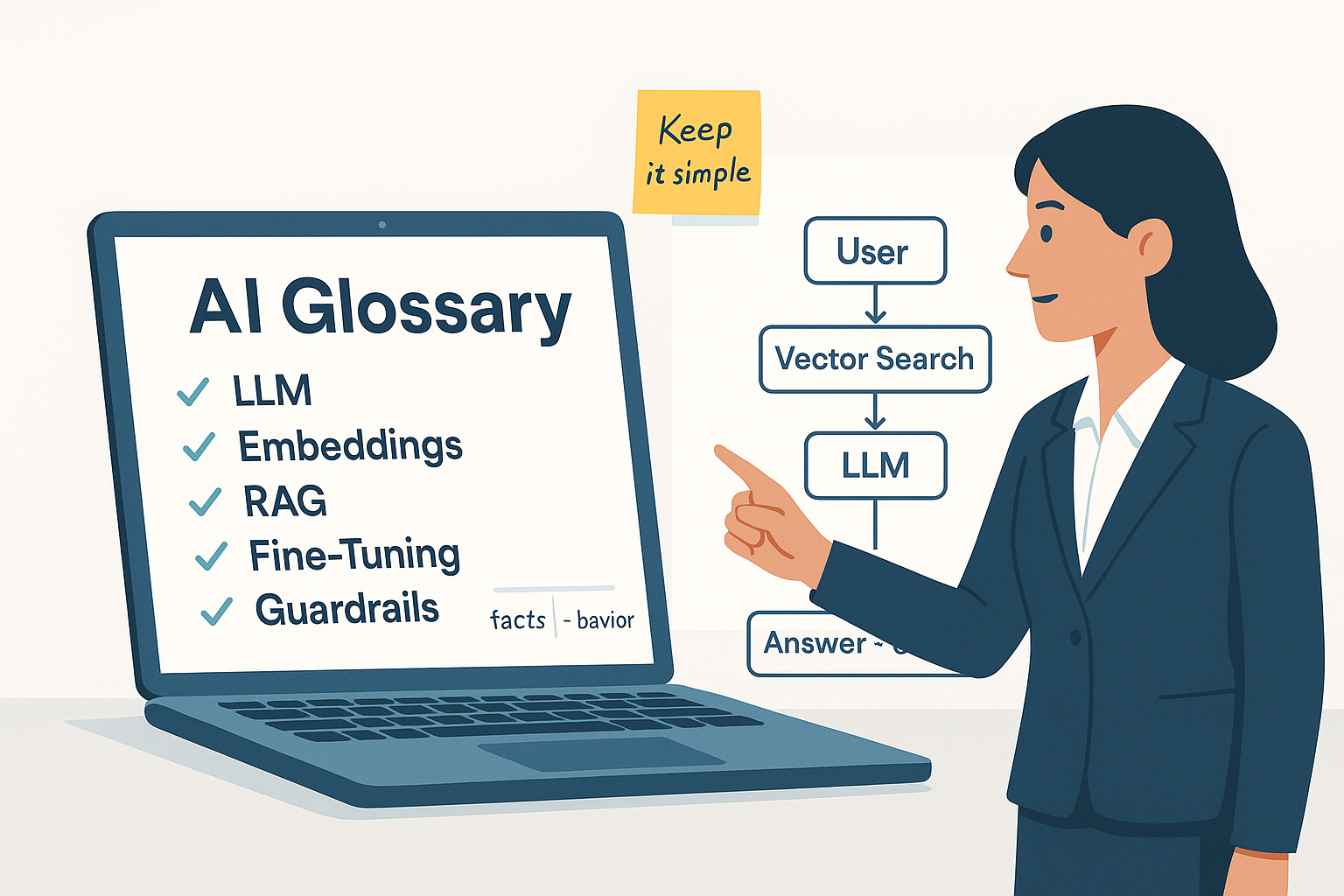
🖼️ Putting it together (one picture)
Most production systems look like this:
User → Prompt/Template → Retrieval (embeddings + vector DB) → Model (with tools) → Guardrails → Output + Citations → Feedback/Eval. If you can describe your design in those blocks, you’re speaking the language.
📌 Key takeaways
Learn the building blocks (LLM, embeddings, RAG, fine-tuning); the rest are variations.
Keep facts in your content (retrieval) and behavior in your model settings/tuning.
Always pair guardrails + evals with any user-facing AI.
Manage the business trade-offs: quality, latency, and cost.
☑️ Executive checklist
Confirm your team uses RAG for factual answers; require citations for critical workflows.
Standardize prompt templates and a system prompt; store them in version control.
Define a small eval set (50–100 real cases) and track a weekly quality score.
Enforce guardrails: PII redaction, content filtering, role-based access, audit logs.
Monitor cost drivers: token counts, context size, and cache hit rate.
Set SLAs for latency and throughput; test under peak loads.
Establish a change process for model swaps, fine-tunes, and retrieval tweaks.
Run periodic red-team tests and review drift; re-embed content on a schedule.
Document data flows and residency; confirm vendor contractual protections.
Educate stakeholders with this glossary; make it part of onboarding.
🧠 Final thoughts
AI vocabulary doesn’t need to be a maze. Learn a few building blocks (LLM, embeddings, RAG, fine-tuning), pair them with guardrails and simple metrics, and you can make confident, fast decisions without getting lost in jargon.
Start with clarity. Define the user problem first; pick the smallest workflow that matters.
Keep facts separate from behavior. Use RAG for knowledge, fine-tuning for tone/format.
Measure what you ship. Track quality, latency, and cost from day one.
Protect the basics. Permissions, PII redaction, audit logs—table stakes for trust.
Iterate in weeks, not quarters. Small eval set, tight feedback loop, steady improvements.
Next 30 minutes:
List one high-volume question your teams repeat.
Identify the 5–10 source docs you’d need to answer it reliably.
Sketch the flow: Prompt → Retrieval → Model → Guardrails → Output + Citations.
If you can describe the system in those blocks—and explain each term in plain English—you’re ready to lead the discussion, not just sit through it.